
真心不给力吗?国产龙芯跟Intel差距到底在哪儿?
- 来源:雷锋网
- 作者:liyunfei
- 编辑:liyunfei
近年来,国内IC设计厂商层出不穷。有龙芯、飞腾、申威等老牌设计单位,也有兆芯、宏芯这些新秀,还有在商业上非常成功的海思、展讯等ARM阵营厂商。但在性能上Intel对各路国产始终保持着巨大的优势,那么国产芯片和Intel的芯片差距在哪里呢?

如何评价各家的CPU性能?
作为消费者来说,自然是希望CPU能尽可能的便宜,而性能经可能高。那么,什么样的CPU性能高呢?从体系结构的角度来看,有个指标叫MIPS,即每分钟执行多少条指令,执行指令数量越多,性能就越好,但这存在一个问题,当CPU指令集不同的时候,比较MIPS就意义不大了——比如A一条指令只算一个加法,B一条指令能做一个1024点的FFT。特别是在不同指令集的情况下,如何评价各家的CPU性能呢?
评价CPU性能必须考虑应用的多样性,比如科学运算重视双精浮点性能,但是如果数据供不上,运算能力再强也没用;比如PC日常使用更偏重于整数性能;再比如计算中心多任务环境关注的是吞吐率......因此单纯用某一个指标来衡量CPU性能是不科学的,必须综合考量。
业界也推出了很多基准测试程序,比如针对CPU的SPEC,针对嵌入式应用的EEMBC等。SPEC测试是比较权威的测试程序,和一些黑箱测试程序不同,SPEC测试的各项程序跑分和计分方式全部公开透明,而且覆盖范围广——SPEC2000有12个定点程序,14个浮点程序,而且有比较强的代表性,比如gzip、vpr、gcc、mef、eon等。
什么是SPEC测试?
SPEC在计分上采用归一化的几何平均方法来进行综合性能评估——将不同CPU的执行时间与参照对象相比较后得到一个相对值。
SEPC2000的参照对象是Ultra SPARC 2工作站的主频为300Mhz的CPU。如果运行测试程序1的时间是参照对象的十分之一的话,测试就是1000分,测试程序2的耗时是参照对象的八分之一的话,则为800分.....最后再算几何平均——比如SEPC2000有12个定点测试,就将12个测试成绩相乘再开12次方,这样以来,测试更加重视性能均衡,因为如果某一项测试存在短板的话,将会大幅拉低测试最后得分,最极端的情况是某项测试为0分,哪怕其他测试分数再高,总分也是0分。
不过SPEC也非尽善尽美,存在不考察I/O带宽和跑分容易受编译器影响等问题。
例来说,龙芯上一代微结构曾因存在访存问题而导致其在SPEC2000下跑分尚可,但在SPEC2006的跑较低,而GS464E解决访存问题后,则不存在这个问题,原因就在于SPEC2000对I/O带宽的要求较低。编译器方面,SUN曾经通过编译器优化提升SPEC跑分50%,龙芯上一代产品用LCC编译器,比使用GCC整数跑分提升了60%。即使同样使用GCC编译器,也会因为不同版本,或优化程度差异导致很难有最准确的评价(GCC部分代码由Intel提供,对X86优化最好,ARM市场份额大,优化也不错,MIPS、ALPHA的优化就比较一般了)。
SPEC测试非常类似于高考,虽然有各种瑕疵,但却有覆盖程序广,公开透明的特点,相对来说比较公平,是可以给CPU做一个相对合理评价的测试程序。
不同指令集CPU比较
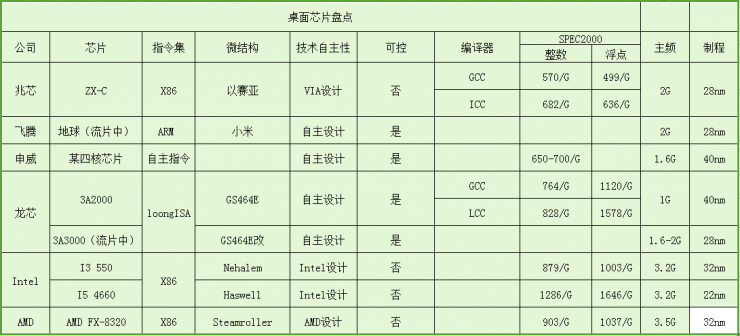
笔者将X86、ARM、MIPS、ALPHA指令集的CPU做了一个表格如下。
编译器除龙芯确定是GCC4.8外,其余都是未知数——VIA的白皮书并没有标明测试中的GCC版本,其余编译器笔者做一个推测:申威可能是SWCC;I3 550、I5 4460可能是GCC5.1。因为仅仅是笔者猜测,严谨起见,编译器选择空白。(ICC是Intel的编译器,X86芯片都可以用;LCC是龙芯的编译器;SWCC是申威的编译器。Intel和AMD的芯片是作参照)
(因编译器不统一,表格仅供参考)
从表中可以看出,使用GCC编译器的情况下,兆芯、申威、飞腾SEPC2000测试和Intel haswell依旧有相当差距,spec2000测试分值最高的GS464E也仅仅是使用自家的LCC编译器的情况下,整数和Nehalem差50分,浮点和haswell差70分。而在主频方面,国内IC设计公司最高主频仅为2G,和Intel、AMD 3G以上主频差距明显。
因此,国产CPU和Intel的差距,不仅仅是主频上的。哪怕兆芯的ZX-C能到达3G以上主频,但因为微结构上的差距,依旧只有I5 4660性能的40%左右,因此微结构非常重要,可以说CPU的安全性、性能、功耗很大程度上取决于微结构,AMD的CPU在同主频下性能逊色于Intel,很大程度上也是因为微结构上的差距。
而在消费者购买CPU时,往往只关注主频、核心数、制程等参数,对微结构往往会忽略,加上Intel这些年从SNB开始挤牙膏,使得微结构更新对性能的提升非常小,导致微结构的重要性更加被忽视。
微结构差距的原因
因为宏芯、兆芯、海思、展讯目前并没有自主设计的微结构,就以龙芯、飞腾最新的两款产品和Intel做比较。以GS464E和IVY的差距而言,通过对比下表参数,就能发现原因。

(数据网络收集,仅供球探足球比分)
如果将GS464E和IVY做对比就能发现,制约GS464E性能的最大的短板在定点发射队列和浮点发射队列上,相对于IVY的54项定点和浮点发射队列,GS464E只有16项定点发射队列,24项浮点发射队列。
龙芯对此也是心知肚明,将正在流片的3A3000,针对GS464E的瓶颈做了改进,将定点发射队列从16项提升到32项,将浮点发射队列从24项提升到32项,并提升了缓存和主频。很显然,虽然龙芯宣称TICK-TOCK,但3A3000相对于3A2000并非单纯的提升主频,定点发射队列和浮点发射队列的提升必然带来IPC的提升。
根据飞腾公布的Spec 2006的模拟器测试,整数为9.6/G。
9.6/G到底是什么水平呢?笔者以Intel作参照,关auto parallel的情况下,haswell 使用GCC5.1 的SPEC 2006的成绩为32分(@3.2G主频)。也就是说,“小米”能接近haswell?
这实在是太“惊悚”了,如果真能做到,就是科技大跃进了。那SPEC2006整数9.6/G的原因何在?根源在于开/关auto parallel。
开auto parallel会导致SEPC2006整数分数增益,因为其将原本单线程执行的程序并行化给多个处理器执行,增益效果取决于编译器、CPU的核心数量等因素。而相当部分常用的代码并不支持auto parallel。因此,目前auto parallel对SPEC跑分更有意义。而“小米”SPEC2006整数高达9.6/G,很有可能就是因为在测试中开auto parallel的结果,那么证据呢?

(数据网络收集,仅供球探足球比分)
从上表中“小米”和IVY的对比中看,“小米”和IVY还是有不小的差距的,并且和GS464E一样存在定点发射队列和浮点发射队列相对IVY偏少的现状,因此在资源有限的情况下,做出达到haswell水平的概率非常小。
对比“小米”和GS464E,假定两者流水线效率相当的情况下,笔者认为“小米”可能是和GS464E一个等级的微结构,并强于ARM Cortex A57。当然,如果流水线效率不佳,“小米”也可能会逊色于GS464E。而“小米”32M的L2缓存,很有可能是因为针对服务器,甚至高性能计算的产物。
目前,飞腾的“地球”和龙芯3A3000正在流片,期待“地球”和3A3000流片归来后的表现。
























玩家点评 (0人参与,0条评论)
热门评论
全部评论