
16384块N卡训练4050亿参数大模型:3小时报错一次
时间:2024-07-29 12:06:05
- 来源:快科技
- 作者:上方文Q
- 编辑:liyunfei
如今的AI大模型规模越来越庞大,动辄成百上千亿参数,训练过程不仅需要数万甚至十几万块GPU加速卡,出错的几率也越来越高。Meta(Facebook)就披露了一份惊人的报告。
Meta在报告中披露,为了训练自己的Llama 3 4050亿参数大模型,使用了包含16384块NVIDIA H100 80GB GPU的集群,一共花了45天,期间居然出现了419次意外报错,平均每3个小时就一次,而一半的错误都和GPU及其自带的HBM3内存有关。

要知道,大模型训练的工作量异常庞大,而且需要高度同步,一次错误就可能导致整个训练工作必须从头再来。
报告显示,为期45天的预训练阶段中,总共出现了466次工作中断,其中47次是计划内的自动维护,419次是意外的,且大部分都来自硬件问题,GPU又是最多的,占了其中的58.7%。
具体来说,148次即30.1%的意外中断来自各种GPU失效(包括NVLink总线),72次即17.2%来自HBM3内存失效——毕竟,700W的功耗太热了。
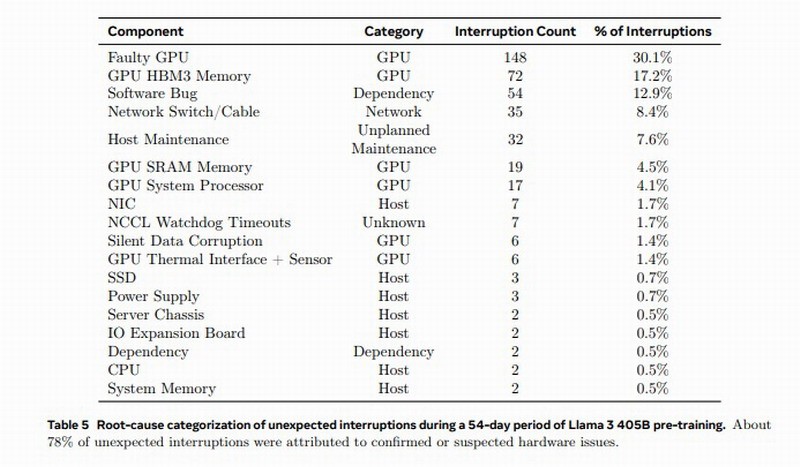
还有19次来自GPU SRAM,17次来自GPU处理器,6次来自GPU静默数据错误,6次来自GPU散热和传感器。
其他错误来自软件bug、网线和网卡等等各个方面。有趣的是,CPU错误只出现了2次。
还好,Llama 3团队非常给力,在这么高的出错几率下,依然维持了超过90%的有效训练时间,而且只有三次GPU报错需要大量人工干预,其他都被自动化管理纠正了。











玩家点评 (0人参与,0条评论)
热门评论
全部评论