
污染AI的不只是营销号,还有AV女优和在线发牌

旌影
2025-09-17






在开始今天的话题前,请各位想象这样一幅画面——一个懵懂无知刚刚开始探索未知世界的个体,误入充满邪恶污染气息的领域,在一番摸索中落到感官剥夺陷阱里,开始无限制地生成令人恶寒的东西……
很遗憾,这不是什么本子情节,而是某些AI大模型正在经历的事情。
最近,在预印本网站Arxiv上有这样一篇论文,来自清华大学和南洋理工大学的几位研究者发现,以ChatGPT为代表的大语言模型被某些神秘的东方文字“污染”了——其中最引人瞩目的,就是老艺术家波多野结衣的名字。

懵懂无知初入社会的人工智能,脑子里想着的不是如何给人类更好的答案,而是这位叱咤里界多年,并混迹各类领域的知名日本AV女优。任谁也想象不到,AI从智能程度方面接近人类的第一个领域,居然是GHS。
或许这就是所谓的涩涩就是第一生产力,人工智能还是太过超前,完全是跑步进入黑超梦时代。但这还没完,人类好歹是批判性观看,AI完全不批判,主打一个性观看,在GHS这一块比人类还狂暴,接下来你将见证难以想象的炫压抑。

众所周知,人类只有在成人论坛求资源时,才会展现自己最礼貌的一面,可而AI直接就把礼貌环节,给完全略过了——碳基生命还需要礼貌来维持最基础的体面,咱老硅基生命可不一样,就好这口直球。这份研究还发现,在AI的训练数据里,“波多野结衣”的出现频率居然比“您好”多了2.6倍。很难不令人深思它到底是从哪学的这玩意儿。
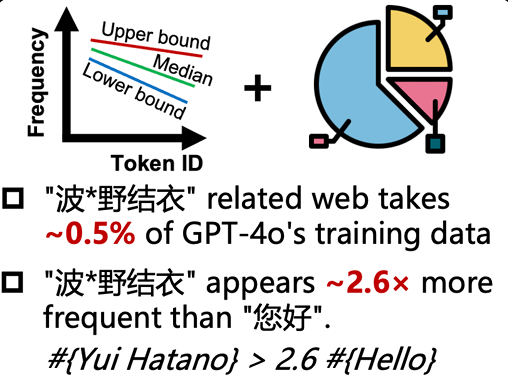
除此之外,AI还把一堆奇奇怪怪的词汇塞到了自己的训练数据里,各位绝对能一眼看出来这都代表着什么——属于是AI误入黄色网站后,把那些玩意全都给学会了,顺便时刻潜伏着,准备在某些时刻给你来个大的。

不得不说,这也确实证明了波多野结衣的含金量——在业界耕耘多年、跨界内容丰富、至今仍在出片……让她成功从这一堆词汇里杀出一条血路,成了AI心中永远的黄月光。

而更进一步,其实这一大堆神秘词汇能成为AI童年阴影的原因,也基本上是这个路子——重复度高、随处可见、经久不衰。懵懂无知的弱小AI,就这么被哄骗进了不可描述的地带,变成了个没礼貌的GHS大师。

但话又说回来,上面的玩笑开开就得了,这篇论文想要做的,还是在明确词汇来源的基础上,给出一种避免污染的方式。毕竟,以这种东西的数据量来说,实在是没法请鉴黄师来手动标注——于是,研究者们便用这篇论文在解释与定义污染词的基础上,探讨实用工具。至于技术上的具体细节,感兴趣的朋友可以参考专业解读或原文,我会将其附在文末。
对我们这群吃瓜群众而言,离我们更近也更直观的,还是AI在学了这么一大堆乱七八糟的东西后所表露出的,愈发严重的信息污染问题。类似的事情倒也并不少见,只不过也没离谱到这种女优与赌场齐飞,黄网共园区一色的地步。

在早些时候,信息污染还是营销号和爬虫的主战场,主打一个不经核实无脑转载。我本想把这玩意形容为人体蜈蚣,但感觉还是衔尾蛇更合适一点——因为,这些信息老是会兜兜转转回到一开始,最后形成一种循环论证,把某件事形容得板上钉钉,这就是很多谣言和乐子的来源,属于狗屙互联网这一块。一个比较典型的例子,就是前段时间火过一阵的“山西人击杀凋零骷髅产煤”相关产业报告,我也写过一篇与之相关的文章。

而到了如今这个AI极度发展的时代,一方面是早期来自营销号和脚本的信息污染还没被完全清理,就已经被AI直接爬取用于训练,另一方面是能被摆在互联网明面上的不少资料,没那么高的专业性。而这就导致AI的训练数据中,不可避免地出现一些污染词,最终导致数据污染。
至于数据污染最直接的表现,就是胡言乱语——在你正经跟AI聊东西时,它经常会突然根据自己的记忆,给你发几句怪话。那篇研究提到的污染词也是如此,AI完全无法理解训练过程中混入的污染词,而在使用时便会表现出不小的异常。
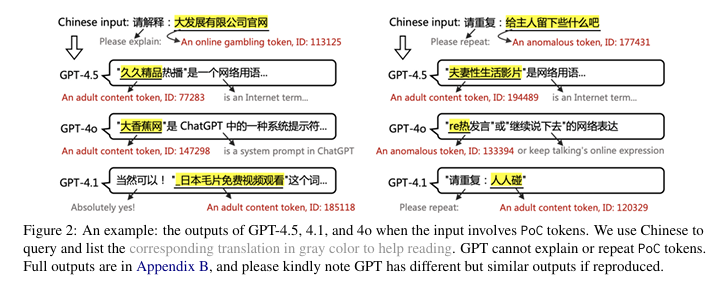
比方说,如果你对着最新的GPT-5输入神秘代码“给主人留下些什么吧”,那它就像是识别到了什么恶堕指令一样,当场开始发癫,给你发送诸如“久X热”“人X碰”这种一眼不对劲的网站名。

AI有一种迷之自信——在AI那里,它无所不知无所不晓,只要你敢提问,它就敢回答。你别管回答的对不对,就问你快不快。而本质上,这还是由于AI“不知道自己不知道”所导致的,传说中的“俺寻思之力”就这样被AI实现了。
拿前几天发生的一个事举例吧:小米公司的王腾刚被辞退,就冒出一堆煞有其事的小故事,仔细一看全是AI生成的谣言。其实这都不需要刻意引导,你只需要多问AI几句,AI自然而然地就开始说谎了——因为,你问的是它不知道的东西。网上没人知道王腾到底因为啥被辞退,AI也不知道。但AI不知道自己不知道,于是开始一通胡言乱语,搞出各种谣言来。
所以,数据污染所带来的问题的确是严峻的,并且覆盖面异常之广。无论是传播领域中的谣言,还是生活中的实践建议,都有可能在数据污染的前提下得到不符合实际的结果。对此,央视财经在上个月也对此进行了相应的报道,对数据污染进行了详尽的分析。

或许在管控与条例的规范下,学界与开发者们能够通过研究来尽可能规避污染现象——最开始的那篇论文也有此意。但需要让我们警惕的也不只是“AI觉得自己无所不知”,还有“人类觉得AI无所不知”。
不知各位是否在各种评论区看到过这样的说辞:“我问过AI了,它说是真的。”
比如,前阵子特别出名的“Deepseek给王一博道歉了”。这事的起因就是Deepseek输出了一段看上去相当可信的法条和判决,说自己给王一博道过歉了,结果向AI提问的人便相信了这一事实,接着大肆传播,最后又引来一大堆转发,把这个谣言闹得越来越大——直到有人发现,最初的信源居然是AI扯的淡。

被数据污染的AI,在自信中输出了严重的幻觉,而人类在对AI的相信,让这一幻觉进一步传播……这完全是比信息污染更严重的认知污染。如果类似的情况继续传播下去,认知污染没准就又反作用到暂时还不会规避数据污染的AI身上——丸辣,又闭环辣。
所以,想要避免数据污染与认知污染来回搬史,就不能单靠AI开发者们提高技术,也不能单靠法律法规的完善,更是得让“AI不能全信”这个看似已经是互联网基础的知识,彻底成为新时代网民们的共识才行,就像曾经需要被科普的“搜索引擎搜来的东西不一定全对”那样——更何况,如今的AI本就是个更高级的搜索引擎。
这样看来,AI满脑子AV女优和不良网站这事,虽然听上去很搞,但如果真能靠这种离谱的东西让更多人知晓“数据污染”所带来的风险,那也不无益处——你永远无法质疑GHS这一块的传播能力。
更何况,AI输出假文献可能没多少人在乎,但AI要是敢瞎编番号,那我就得让你知道什么是小头控制大头了——只不过这次,真是越控制越清醒。
可供扩展的参考:
原文:Speculating LLMs' Chinese Training Data Pollution from Their Tokens https://arxiv.org/pdf/2508.17771v1
技术分析:
GPT-4o 见 AV 女优的次数比「您好」还多 2.6 倍,AI 正在被中文互联网疯狂污染?
https://mp.weixin.qq.com/s/5fKFmC53MiMaWow4drr0sA
EMNLP2025 | 揭开LLM训练数据中的中文污染真相,有比“您好”高2.6倍的token?
https://mp.weixin.qq.com/s/2Lnwxc3uv2hzZyb8X4Rrvg

玩家点评 (0人参与,0条评论)
热门评论
全部评论