
全新架构来袭:Radeon HD 6970/6950详尽评测
- 来源:驱动之家
- 作者:batyeah
- 编辑:ChunTian
Radeon HD 6900全新内核架构之4D图形与计算
无论开发什么新产品,设计人员总要首先设定一些预期目标,然后通过技术上的努力去实现,从而满足市场和用户的需要。可以说,只有合理的目标与顺利的执行有机结合才能诞生一款优秀的产品。
在Cayman Radeon HD 6900系列身上,AMD就提出了四大目标:高效的图形与计算架构、强大的几何性能、新的画质技术、新的能效与功耗管理。下边我们就从这四个方面着手,细细品位Radeon HD 6900的内核架构与技术精髓。

为了实现高效的图形与计算架构,AMD该用了重新定义的VLIW4架构,同时还引入了双图形引擎、更多SIMD引擎与纹理单元、升级的渲染后端、更高的显存带宽、新的GPU计算技术。


VLIW全称为Very Long Instruction Word,意思是超常指令字架构,是一种非常长的指令组合,通过把许多条指令连在一起来增加运算的速度。从第一代DX10 R600内核开始,AMD就一直使用VLIW5方式,又称5D式,也就是五个流处理器编为一组,但并非所有流处理器都是相同的,其中四个较小、较简单,另一个较大、较复杂做为特殊单元。这种架构设计在硬件方面看有着很高的效率和很深的潜力,但是结构比较复杂,对应的软件编程就很困难,始终难以真正发挥全部实力。
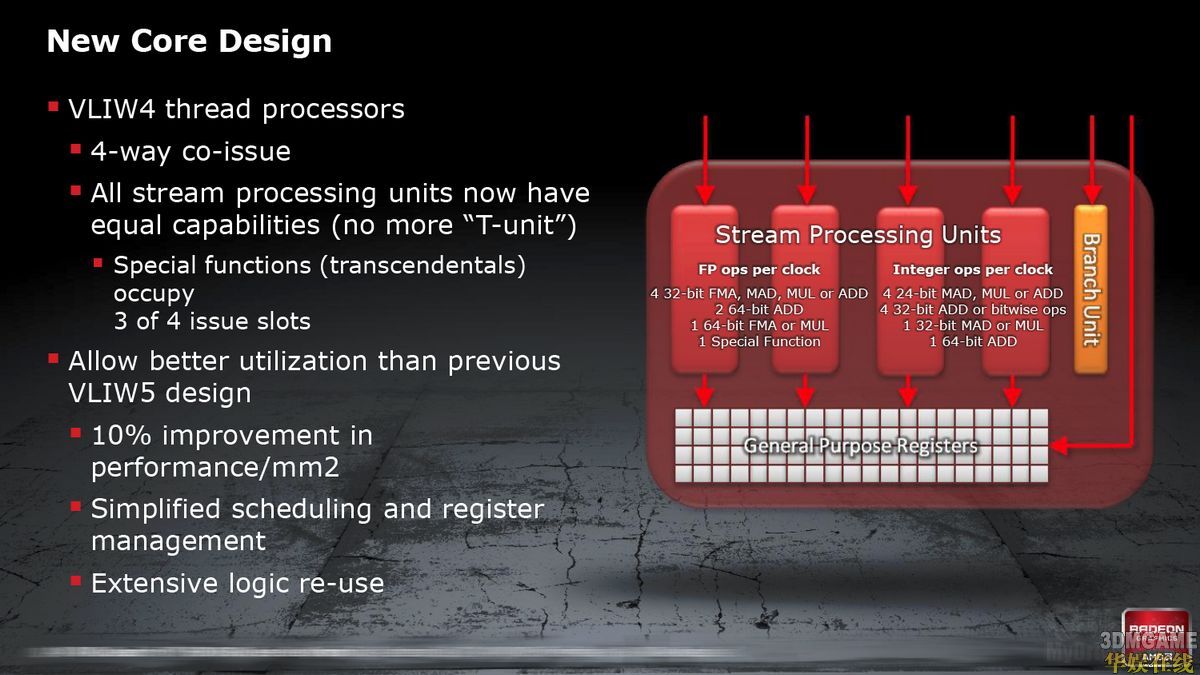
如今AMD终于在内核层面翻新为VLIW4方式(4D式),每个编组由四个流处理器、一个分支单元、一个通用目的寄存器组成,其中四个流处理器的整数、浮点执行功能完全相同(不再有T-Unit),可以执行四路并行发射,但是特殊功能占据四个发射位中的三个。
AMD宣称,VLIW4架构有着更好的利用率,能将性能与核心面积比提高10%,简化调度与寄存器管理,逻辑核心也可以很好地重复使用。
除了前端,渲染器后端也进行了升级,支持写入操作合并,16位整数操作提速两倍,32位浮点操作也快了两到四倍。

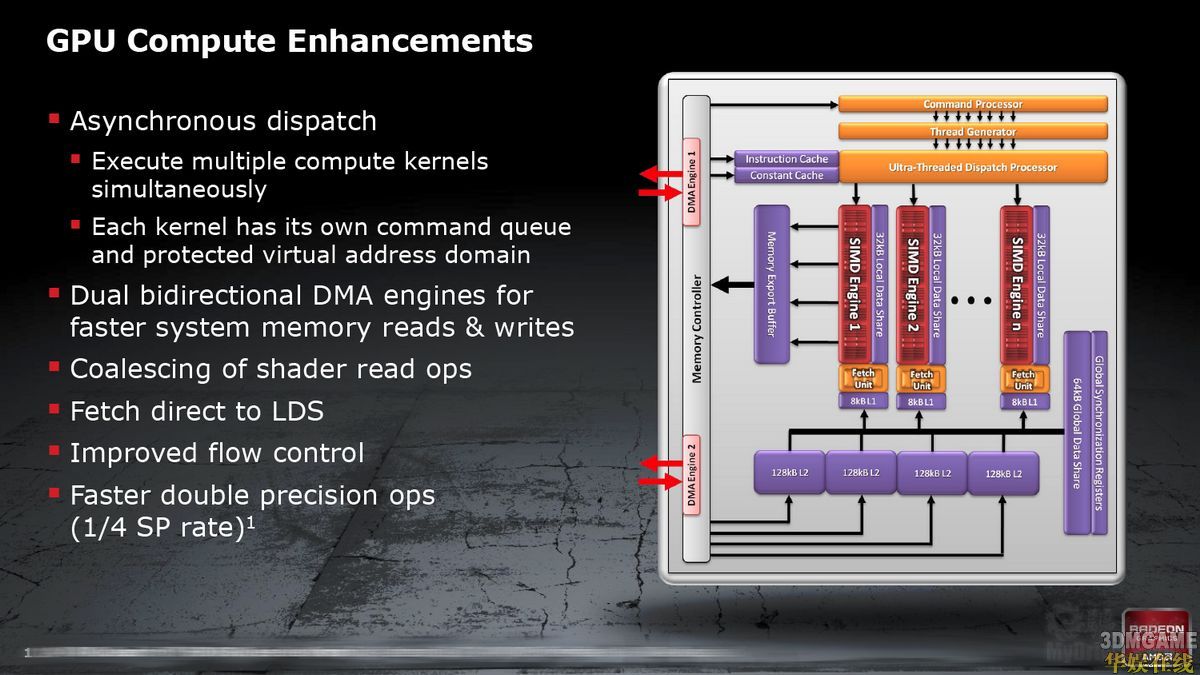
GPU并行计算方面,新内核最大的亮点就是增加了一个全局异步寄存器,从而支持异步分配,可以同时执行多个计算内核,每个内核都有自己的命令队列与受保护虚拟寻址域。此外还有两个双向DMA引擎(更快的系统内存读写速度)、着色器读取操作合并、LDS(本地数据存储)直接预取、流控制改进、更快双精度操作(单精度的1/5提高到1/4)。

























玩家点评 (0人参与,0条评论)
热门评论
全部评论